 لم ينقطع الحديث عن “ذكاء الآلة” منذ ظهور الكمبيوتر الأول. وخلال العقد الأخير تحديداً ومع تطوّر الهواتف الذكية وشبكات الاتصال، بدا أن تطبيقات من قبيل “سيري” تبشِّر بذكاءٍ آلي حقيقي، فهي تفهم ما نقول وتحوّل ألفاظنا إلى نصوص تستنبط منها المطلوب. كما يسعنا أن نستشهد بمترجم “غوغل” الذي يترجم النصوص بين أكثر من 70 لغة، ولو بدرجات متفاوتة من الدقة والجودة. والقائمة تستمر؛ كمبيوترات تؤلِّف مقطوعات موسيقية ونصوصاً شعرية ومقالات نثرية، يصعب على المرء أن يفرِّق بينها وبين الإنتاج البشري. بل يخوض علماء الكمبيوتر اليوم في عوالم الوعي الآلي ليقدِّموا لنا أجهزة تقوم بما يشبه التخيّل التصويري أو بعبارة أبسط: أجهزة تحلم!
لم ينقطع الحديث عن “ذكاء الآلة” منذ ظهور الكمبيوتر الأول. وخلال العقد الأخير تحديداً ومع تطوّر الهواتف الذكية وشبكات الاتصال، بدا أن تطبيقات من قبيل “سيري” تبشِّر بذكاءٍ آلي حقيقي، فهي تفهم ما نقول وتحوّل ألفاظنا إلى نصوص تستنبط منها المطلوب. كما يسعنا أن نستشهد بمترجم “غوغل” الذي يترجم النصوص بين أكثر من 70 لغة، ولو بدرجات متفاوتة من الدقة والجودة. والقائمة تستمر؛ كمبيوترات تؤلِّف مقطوعات موسيقية ونصوصاً شعرية ومقالات نثرية، يصعب على المرء أن يفرِّق بينها وبين الإنتاج البشري. بل يخوض علماء الكمبيوتر اليوم في عوالم الوعي الآلي ليقدِّموا لنا أجهزة تقوم بما يشبه التخيّل التصويري أو بعبارة أبسط: أجهزة تحلم!
يعود الفضل لكثير من مظاهر التقدُّم التقني في مجال الذكاء الاصطناعي لما يُعرف بالتعلُّم الآلي “Machine Learning”. الذي ظهر كعلم معتبر في خمسينيات القرن الماضي، ولكنه لم يبدأ بتحقيق إنجازاته الكبيرة إلا في العقدين الأخيرين ليصبح جزءاً أساسياً في تطبيقات شتى اقتصادية وأمنية وصحيّة.
والتعلُّم الآلي هو مجموعة من الأساليب والطرق المختلفة التي يستخدمها مهندسو الكمبيوتر لـ”تدريب” البرنامج الحاسوبي على القيام بمهمة تصنيف معيَّنة، بما يقدّم إجابات عن أسئلة من قبيل:
• هل رسالة الإيميل هذه حقيقية، أم هي رسالة تصيدية (Phishing)؟
• هل التعبير على الوجه الذي في الصورة هذه مبتسم؟ أم حزين؟ أم غاضب؟ أم متقزز؟
• هل الشخص لديه مجموعة التحاليل الطبية هذه، والتاريخ الطبي العائلي هذا، مريض أم لا؟
• ما هو الكائن الذي في هذه الصورة؟ هل هو قط؟ أم إنسـان؟ أم حصان؟
كيف يتم تدريب الكمبيوتر على التعلُّم الآلي؟
الخطوة الأساسية لتدريب الكمبيوتر على القيام بإحدى مهمات التصنيف السابقة هي أن نبدأ بتجميع المعلومات المتعلِّقة بها. تحديداً، وعلينا أن نُعرِّف المشكلة التي نحاول أن ندرّب الكمبيوتر على حلها. وهذا يعني أن نقوم بالتالي:
تحديد الأصناف “Classes”
المقصود بتحديد الأصناف، هو تسمية الأصناف أو الأقسام التي يمكن أن يُصنَّف إليها. فمثلاً، إذا كانت المشكلة التي نحاول حلّها هي “ما التعبير الذي على الوجه في هذه الصورة؟”، فعلينا أن نحدِّد مسبقاً الأنواع المختلفة للتعابير، مثل: سعيد، حزين، أو غاضب. ويعتمد تحديد الأصناف هذه بشكل مباشر على السؤال نفسه. بعبارة أخرى، يمكننا أن نقول إن ما نحاول تحديده هنا هو الإجابات المقبولة للسؤال المطروح.
تجميع أمثلة “Examples” على هذه الأصناف
وهي الأمثلة الواقعية والمرجعية لهذه الأصناف. فمثلاً، إذا كانت الأصناف التي لدينا محدودة بثلاثة: سعيد، حزين، وغاضب؛ فعلينا تجميع صور لأشخاص وهم سعداء، وأخرى لأشخاص حزينين، وثالثة لأشخاص غاضبين.



By Cohn-Kanade
تحديد سمات “Feature” الأمثلة
سمات الأمثلة هي مجموعة من الصفات التي تتَّسم بها الأمثلة. والكمبيوتر سيستخدم هذه السمات ليتعرَّف بشكل أفضل على الأصناف التي حددناها سابقاً. ولكن من المهم أن تكون هذه السمات كميّة؛ أي يمكننا تسجيلها ورصدها وقياسها ككميات رقمية. فالكمبيوتر يتعامل فقط مع الأرقام. ولا يمكننا أن نقول للكمبيوتر إنَّ إحدى سمات التعبير السعيد هو بريق العينين أو انثناء الشفتين في شكل ابتسامة، فالكمبيوتر لا يفهم ماذا يعني أن يكون الفم مبتسماً! وهكذا فنحن لا يمكننا أن نعطيه سمات كيفية أو اعتبارية.
يعتمد تحديد السمات بشكل كبير على نوع الأمثلة التي لدينا. ففي حالة كون الأمثلة صوراً، يمكننا استخراج سمات كمية رقمية منها باستخدام طرق تُعرف بـ”معالجة الصور ” التي تأخذ الصور وتستخرج منها مجموعة من السمات البسيطة التي يمكن التعبير عنها رقمياً. إحدى طرق معالجة الصور هذه تعرف بالكشف عن الحواف (Edge Detection). فكل الصور هي عبارة عن مجموعة من النقاط تعرف باسم البيكسلات. وتقوم طريقة الكشف عن الحواف بتحويل كل نقطة بيكسل في الصورة إلى نقطة سوداء أو بيضاء بناءً على كون هذه النقطة جزءاً من حواف شكل أو جسم معيَّن في الصورة:

كل نقطة بيكسل يمكننا أن نعدها سمة تعبِّر عن مكان وجود الحدود في الصورة. وهذه السمة هي سمة كمية لأن كل بيكسل في ملف الصور سيترجم إلى ملف رقمي يحمل قيمة ثنائية (واحد أو صفر، أسود أو أبيض). وبطبيعة الحال، فتلك ليست السمات الوحيدة التي يمكن استخراجها من الأمثلة التي لدينا. وهناك عشرات إن لم تكن مئات من الطرق المختلفة لاستخراج سمات كمية من الصور.
اختيار نموذج التعلُّم الآلي
 الآن وقد صارت لدينا الأمثلة التي نريد تصنيفها، والسمات الكمية التي تُعبّر عنها، علينا أن نختار أحد نماذج التعلُّم الآلي المتاحة.
الآن وقد صارت لدينا الأمثلة التي نريد تصنيفها، والسمات الكمية التي تُعبّر عنها، علينا أن نختار أحد نماذج التعلُّم الآلي المتاحة.
نموذج التعلُّم الآلي هو تجريد رياضي يُفترض أن يحاكي عملية التعلُّم من الأمثلة. والتجريد الرياضي هو طريقة تستخدم في العادة لمحاكاة بعض الظواهر الطبيعية. فمثلاً، إذا أردت أن تعرف كم من الوقت سيستغرقه سقوط كرة من أعلى برج، فأمامك خياران لحساب ذلك. الأول هو الخيار التجريبي بأن ترمي هذه الكرة فعلاً من أعلى البرج وتستخدم ساعة لتحسب كم مضى من الوقت. والخيار الآخر هو أن تقوم بتجريد هذه المسألة رياضياً وحلّها على الورق، وذلك بواسطة اعتبار الكرة كجسم منتظم وتجاهل وجود مقاومة الهواء واعتبار انتظام قوة الجاذبية، وثم استخدام معادلات الفيزياء لحساب الوقت الذي سيستغرقه سقوط الكرة. طبعاً، كما هو واضح من المثل، يعتمد التجريد الرياضي على تجاهل أو اختزال الواقع بمجموعة من المعادلات الرياضية التي تقدِّم لنا مقاربة للواقع وإن كانت تحمل نسبة خطأ طفيفة. وبالمعنى نفسه هذا للتجريد الرياضي، يقوم نموذج التعلُّم الآلي بأخذ سمات مثال معيَّن، وباستخدام مجموعة من المعادلات التي تقارب الواقع، سيعطينا جواباً على ما هو صنف هذا المثال المعطى. هناك عديد من النماذج الرياضية المختلفة التي يمكن استخدامها للتعلُّم الآلي. ولكل منها سلبياته وإيجابياته. فبعضها قادر على إعطاء نتائج حتى مع شُح الأمثلة، وبعضها الآخر يعمل بشكل أفضل مع أشكال معيَّنة من الأمثلة دون غيرها، كأن يعمل بشكل جيد مع تصنيف المشكلات المتعلَّقة بالنصوص ولكن ليس بنفس المستوى مع المشكلات المتعلَّقة بالصور.
تدريب نموذج التعلُّم الآلي
نموذج التعلُّم الآلي كما ذكرنا هو عبارة عن مجموعة من المعادلات الرياضية التي تأخذ السمات الكمية للأمثلة لتعطينا جواباً بخصوص أي صنف تنتمي إليه هذه الأمثلة. لكن ما يجعل هذه النماذج مختلفة عن معادلات القوانين الفيزيائية، هو أن معادلات هذه النماذج تمتاز بقابليتها للمعايرة أو التعديل الطفيف بما يسمح بتحسينها. وهذا يعني أننا بتغيير بسيط لهذه المعادلات يمكننا أن نغيِّر من مدى تأثير بعض السمات التي يأخذها النموذج على الجواب النهائي. فمثلاً يمكننا بتعديل بسيط أن نتجاهل بعض السمات بشكل كامل، أو أن نهتم بقسم منها دون البقية.
وتعتمد عملية تدريب نموذج التعلُّم الآلي على عمليات المعايرة والتعديل البسيطة هذه. فخلال عملية التدريب، نعطي الكمبيوتر أحد الأمثلة التي لدينا ولنفترض أنها صورة لشخص سعيد. ثم نقوم بتعديل المعادلات التي في نموذج التعلُّم الآلي بحيث نثبت جواب النموذج على صنف هذه الصورة على أنها صورة لشخص سعيد. بعد ذلك، نعطي النموذج المثال الثاني، وهذه المرة أيضاً نقوم بتعديل معادلات النموذج حتى يعطينا الجواب الصحيح لصنف هذه الصورة، ولكن الفرق أننا نريد أن نقوم بالتعديل بحيث يبقى الجواب عن الصورة الأولى صحيحاً. ونستمر بهذه الطريقة بإعطاء الكمبيوتر المثال تلو المثال، ومع كل مثال يأخذه فإنه سيكتسب خيرة تراكمية تمكِّنه من تعديل معادلات نموذج تعلّمه الآلي حتى يكون قد تدرَّب على كل الأمثلة التي لدينا، لنتركه يعتمد على نفسه لاحقاً.
استخدم النموذج الذي درَّبته!
بعد أن تمَّ تدريب النموذج على الأمثلة المعطاة له، كل ما علينا الآن فعله هو أن نأخذ عيِّنة اختبار جديدة لم يرها الكمبيوتر من قبل. ثم نستخرج السمات الكمية لهذه العيِّنة مثلما فعلنا مع الأمثلة التي استخدمناها لتدريب نموذج التعلم الآلي. بعد ذلك نعطي هذه السمات الكمية لنموذجنا، سيعطينا النموذج جواباً على ماهية صنف عيِّنة الاختبار هذه، وفي الغالب إذا كانت هذه العيِّنة تشبه بعض الأمثلة التي درَّبنا النموذج عليها سيكون الجواب صحيحاً.
الحُلم العميق (DeepDream)
والآن لنعد إلى السؤال “هل يحلُم الحاسوب؟”. وللجواب عن هذه السؤال علينا أن ننظر إلى برنامج “الحُلم العميق”. هذا البرنامج أطلقته شركة (غوغل) في منتصف عام 2015، ويقوم بتخليق وإنتاج صور تبدو وكأنها منبثقة من عالم الأحلام وكانت نتائج هذا البرنامج مذهلة وفاتنة.

 وبعد (أسفل) تطبيق عشرة تكرارات من الحلم العميق By MartinThoma")
وما يقوم به برنامج “الحلم العميق” هو أخذ صورة والقيام بتعديلها لإظهار سمات فيها لم تكن ظاهرة أو حتى موجودة من قبل. فماذا يفعل بالتحديد؟ وكيف يقوم بإنتاج هذه الصورة العجيبة والمثيرة للدهشة؟!
مجرد شبكة عصبونية
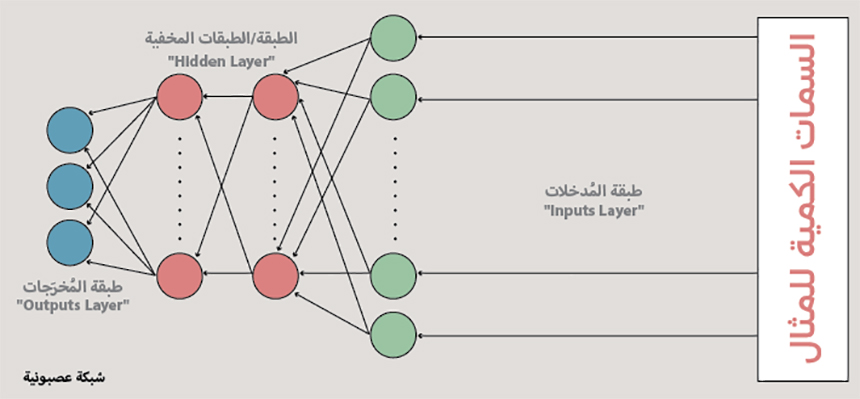
برنامج “الحُلم العميق” هو عبارة عن شبكة عصبونية (Neural Network). والشبكات العصبونية هي أحد أشهر نماذج التعلُّم الآلي التي تحاول محاكاة وتجريد التعلُّم البشري. تعود أصول الشبكات العصبونية إلى أواسط القرن العشرين. وكان قد تم تصميمها في محاولة لمحاكاة تصميم العصبونات الحيوية في الحيوانات. وهي عبارة عن مجموعة من العصبونات “Neurons” التي يمثل كل منها عملياً معادلة رياضية. فكل عصبون يتصل بعصبونات أخرى يأخذ منها مدخلاته، وعصبونات أخرى تأخذ بدورها منه مدخلاتها.
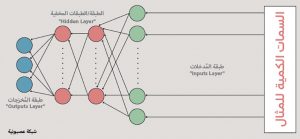
مكونات الشبكة العصبونية:
تتكوَّن الشبكة العصبونية بشكل رئيس من ثلاثة أنواع من الطبقات:
– طبقة المُدخلات (“Inputs Layer”) (اللون الأخضر): وهي الطبقة التي تأخذ سمات المثال في شكلها الرقمي الأولي. كل عصبون في هذه الطبقة مسؤول عن إدخال سمة واحدة من المثال.
– الطبقة / الطبقات المخفية (“Hidden Layer”) (اللون الأحمر): كل طبقة مخفية تأخذ مُدخلاتها من الطبقة التي سبقتها، ليتم استخدامها كمتغيرات “Variables” في معادلة. ولكل من هذه المتغيرات في المعادلة توزين معيَّن يتم تمثيله رياضياً بمعامُل. واختيار المعادلات يعتمد على حاجات تدريب الشبكة العصبونية، ويحدِّد كيفية استمثال النموذج، ويحدّد أيضاً مدى سهولة أو صعوبة القيام بذلك.
– طبقة المُخرَجات (“Outputs Layer”) (اللون الأزرق): تعرف هذه الطبقة أيضاً باسم طبقة الأصناف (Classes). فكل عصبون في هذه الطبقة يمثِّل صنفاً من الأصناف التي حددناها مسبقاً. وفي هذه الطبقة أيضاً، كما الطبقات المخفية، يمثل كل عصبون معادلة رياضية تعتمد على مُخرَجات عصبونات الطبقة الأخيرة المخفية. ويمثل ناتج كل من هذه العصبونات في طبقة المُخرَجات مدى احتمال كون المثال المُدخل من الصنف الذي يمثله العصبون.
وكأي برنامج تعلُم آلي، بدأ مشروع (DeepDream ) بتحديد الأصناف المراد تخمينها. وهنا اختار المهندسون حوالي 1000 صنف، كل صنف عبارة عن شيء موجود في حياتنا اليومية: إنسان، كلب، قط، حصان، مبنى، سيارة، درَّاجة، هاتف، إلخ… ثم قام المهندسون بتجميع أمثلة على كل هذه الأصناف. جمع المهندسون أكثر من مليون صورة وقاموا بتصنيف كل صورة من هذه المليون صورة إلى صنف من الألف صنف التي تم تحديدها. بعدها قاموا بتدريب نموذج الشبكة العصبونية عبر إعطاء النموذج المثال تلو الآخر من المليون مثال التي لديهم. ومع كل مثال يتم تغيير وتعديل المعادلات الرياضية التي في نموذج تعلُّم الشبكة العصبونية لتصبح إجابات الشبكة عن أصناف الأمثلة أحسن وأحسن.
وبالفعل، أصبح لدى المهندسين شبكة عصبونية قادرة على تصنيف أي صورة بشكل فعَّال ومثير للإعجاب. ولكن المهندسين أخذوا البرنامج خطوة إضافية للأمام، جعلت من “الحُلم العميق” أكثر من مجرد مصنِّف للصور.
أحلام اليقظة: ماذا يفكِّر كل عصبون؟
أراد المطوِّرون لبرنامج “الحُلم العميق” أن يدرسوا النموذج الذي استخدموه عن قرب. ولكن المشكلة التي واجهتهم هي أنه على الرغم من أن البرنامج يستطيع أن يقوم بمهمته كمحدد لصنف أي صورة يأخذها، إلا أنه عبارة عن صندوق أسود. فالمعادلات التي في كل عصبون من عصبونات الشبكة لا تحمل معنى ظاهراً بشكل مباشر. لذا أراد الباحثون أن يفهموا دور كل من عصبونات الشبكة على حدة. هل يمكن أن يكون كل عصبون يحاول أن يمثِّل وجود صفة كيفية في الصورة المعطاة؟ فمثلاً، إذا كان لدينا كثير من أمثلة على صور لقطط، هل من الممكن أن نجد أن بعض العصبونات تمثِّل وجود فرو؟ وأخرى تمثِّل وجود مخالب؟ وأخرى تمثِّل وجود شوارب؟
للإجابة عن هذه الأسئلة، قام المهندسون بتجربة عبقرية. بعد أن تم الانتهاء من نموذج الشبكة العصبونية، اختار المهندسون مجموعة من العصبونات التي أرادوا دراستها من الشبكة. وللقيام بذلك، أعطوا الشبكة صورة كهذه:

ومن ثم بدأوا بالتدريب ولكن هذه المرة بشكل عكسي. فبدلاً من تعديل معادلات الشبكة للإجابة عن ماهية الصورة، بدأ المهندسون بتعديل سمات الصورة بحيث ترتفع قيم المعادلات التي في العصبونات التي اختاروها سابقاً. فمثلاً، عند اختيار مجموعة معيَّنة من العصبونات قامت عملية التدريب العكسي بتعديل الصورة إلى هذه الحالة:

وبهذه الطريقة، استطاع المهندسون أن يروا بأعينهم ما تمثله العصبونات التي اختاروها هنا. فمن الصورة يبدو أن العصبونات التي اختاروها تمثل عدداً مختلفاً من الأجسام كالأبنية ذات القبة، والكلاب، وربما بعض السيارات الصغيرة.
والتعديل الذي سيطرأ على الصورة، يعتمد على العصبونات التي نختارها. فمثلاً هذه الصورة هي نتيجة التدريب العكسي على عدد أصغر من العصبونات:

هذه الصورة تلمّح لنا أن هذه العصبونات تمثِّل بعض الخصائص الأكثر تجريداً. فيبدو أنها تقوم بتمثيل خصائص كتموج الصورة، أو انسيابية المظهر، أو الحدود والأطراف.
ومن خلال تحديد مجموعة أخرى من العصبونات، استطاع المهندسون تحديد العصبونات التي تمثِّل بعض الخصائص الأكثر تعقيداً. فمثلاً لننظر إلى هذه الصورة:

ويبدو من هذه أن العصبونات التي اختيرت هنا تمثِّل خاصتي الأعين، والفراء.
مرآة لذهننا؟
 كل هذه التمثيلات التي نرى العصبونات تقوم بها تجعلنا نتساءل، هل هذا ما يحدث في أدمغتنا؟ فكما ذكرنا، تم تصميم الشبكات العصبونية لمحاكاة كيفية عمل الخلايا العصبية في الدماغ البشري. وهنا نستطيع لأول مرة أن نستكشف هذه المحاكاة لدماغنا. ولكن مدى دقة هذا النموذج ومدى مصداقية محاكاته للحقيقة هي محل شك. ولكن أيا يكن الحال، لا يسعنا عند النظر إلى هذه الصور التي ينتجها “الحلم العميق” إلا أن نتصور أن هناك بوادر للإدراك في الكمبيوتر. فنحن نرى بأم أعيننا كيف تستطيع العصبونات أن تمثِّل أفكاراً مجردة وتصويرية للأجسام. وربما ما يثير الإثارة هو أن نفس التصميم الشبكي العصبوني الذي يستخدمه (الحُلم) العميق” تستخدمه غوغل في منتجات أخرى على رأسها مترجم غوغل. فإذا كانت العصبونات تستطيع تمثيل مفاهيم تصويرية عن تغذيتها بصور، هل من المعقول افتراض أن عصبونات الشبكة المستخدمة في مترجم تمثل مفاهيم لغوية؟ ماذا عن مجالات أخرى كالتأليف الموسيقيّ؟ كل هذه الأسئلة تتطلَّب تجارب عملية كالتي قام بها مهندسو غوغل في “الحُلم العميق”. ولكنها تتطلَّب أيضاً الاستعانة بتحليلات فلسفية لفهم معنى ما يحدث في هذه الآلات. وهذا ما يجعل مجال التعلُّم الآلي مثيراً جداً، فهو يسمح لنا بطرح أسئلة فلسفية عن أنفسنا وعن وعينا باستخدام أساليب وأدوات لم نكن نحلُم بها!
كل هذه التمثيلات التي نرى العصبونات تقوم بها تجعلنا نتساءل، هل هذا ما يحدث في أدمغتنا؟ فكما ذكرنا، تم تصميم الشبكات العصبونية لمحاكاة كيفية عمل الخلايا العصبية في الدماغ البشري. وهنا نستطيع لأول مرة أن نستكشف هذه المحاكاة لدماغنا. ولكن مدى دقة هذا النموذج ومدى مصداقية محاكاته للحقيقة هي محل شك. ولكن أيا يكن الحال، لا يسعنا عند النظر إلى هذه الصور التي ينتجها “الحلم العميق” إلا أن نتصور أن هناك بوادر للإدراك في الكمبيوتر. فنحن نرى بأم أعيننا كيف تستطيع العصبونات أن تمثِّل أفكاراً مجردة وتصويرية للأجسام. وربما ما يثير الإثارة هو أن نفس التصميم الشبكي العصبوني الذي يستخدمه (الحُلم) العميق” تستخدمه غوغل في منتجات أخرى على رأسها مترجم غوغل. فإذا كانت العصبونات تستطيع تمثيل مفاهيم تصويرية عن تغذيتها بصور، هل من المعقول افتراض أن عصبونات الشبكة المستخدمة في مترجم تمثل مفاهيم لغوية؟ ماذا عن مجالات أخرى كالتأليف الموسيقيّ؟ كل هذه الأسئلة تتطلَّب تجارب عملية كالتي قام بها مهندسو غوغل في “الحُلم العميق”. ولكنها تتطلَّب أيضاً الاستعانة بتحليلات فلسفية لفهم معنى ما يحدث في هذه الآلات. وهذا ما يجعل مجال التعلُّم الآلي مثيراً جداً، فهو يسمح لنا بطرح أسئلة فلسفية عن أنفسنا وعن وعينا باستخدام أساليب وأدوات لم نكن نحلُم بها!



































 وبعد (أسفل) تطبيق عشرة تكرارات من الحلم العميق By MartinThoma")






